
這幾天看到好友的文章關于while(1)和for(;;)效率的討論,手癢說了兩句。回頭一尋思,自己也只是推斷。沒有做任何實驗,我們就看看這兩種寫法到底有什么區別:
實驗環境:IAR EWARM 5.2
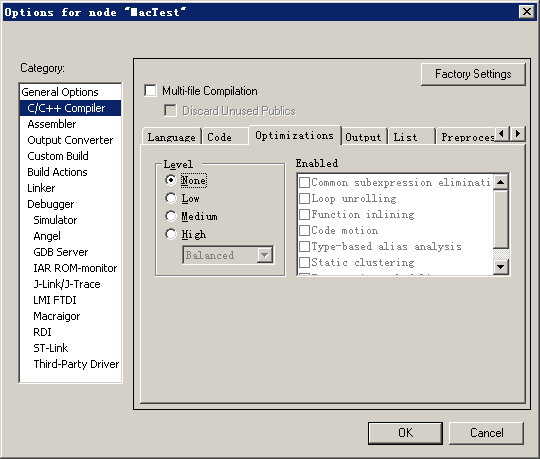
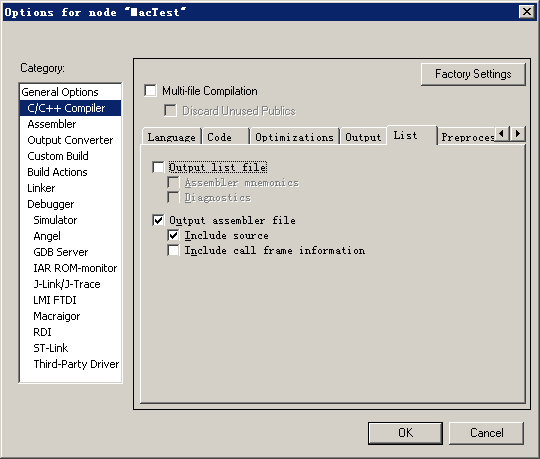
我就隨便在一個嵌入式項目上做文章了,首先工程C語言編譯優化選擇了None, 輸出選擇帶匯編輸出,輸出的匯編文件和C語言對應上。
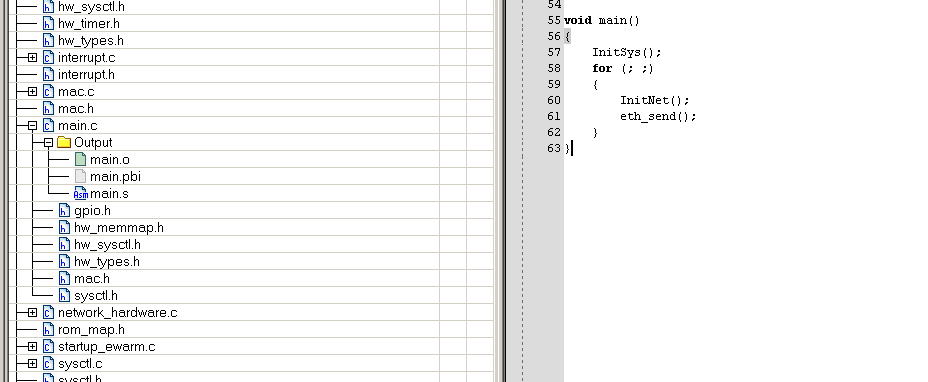
我在main函數里先用for(;;)寫了個死循環,我們看看編譯結果:
注意main.c生成了一個對應的main.s

可以看到,是用一條跳轉指令直接替代的for (;;)。
再更改一下代碼:
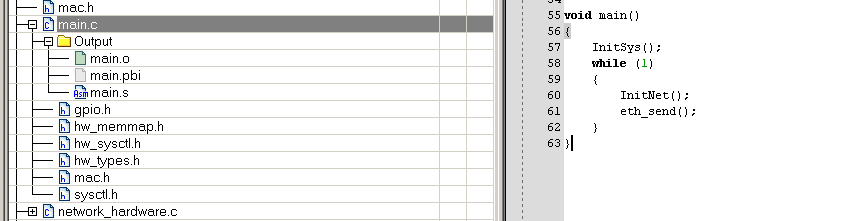
編譯一下看結果:
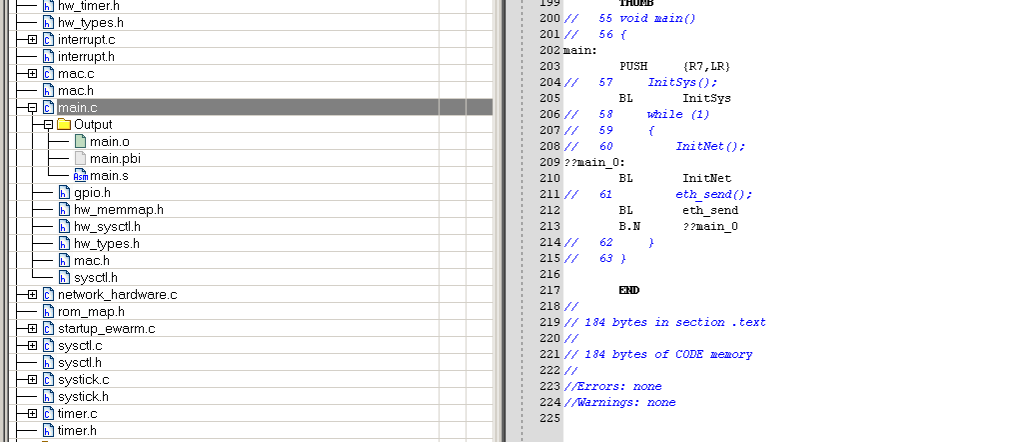
while(1)的循環也是一句跳轉指令所替代。
IAR EWARM 5.2下,可見 for(;;)和while(1)在未開優化代碼級別下,完全一樣。無任何區別。
我們再來看看 linux 下的arm-rtems4.9-gcc的結果:

我寫了一個很簡單的代碼:

先看看 while (1)的編譯結果:
使用圖形中的命令依次鍵入:
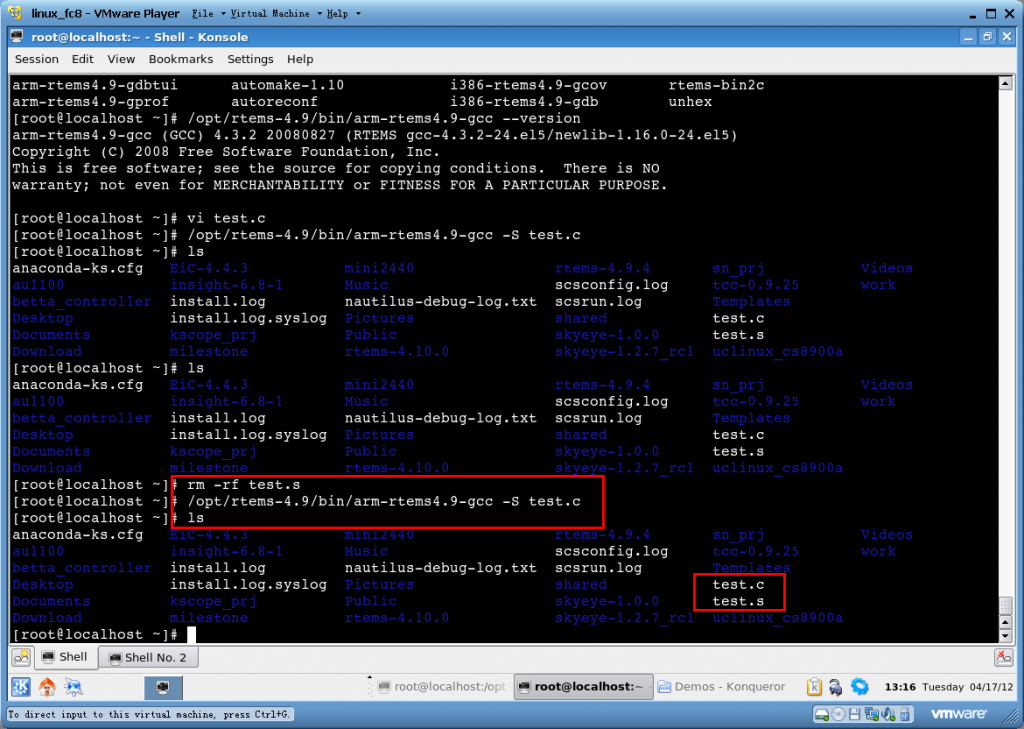

可以看到,while(1)循環已經變成了一個b .L7,并沒有對1做判斷。也是1條指令就搞定了。
我們再來看看for(;;)

鍵入以下命令:

查看結果如下:

兩個結果是一樣的。同樣,gcc我也沒有打開優化,如果需要看優化編譯匯編結果的朋友們,可以使用gcc -O2 -S test.c,也可以使用 gcc -Os -S test.c,-Os在嵌入式里用得多一些。沒有優化的代碼都是一樣的,更不要說優化過的代碼。
其實這是個挺蛋疼的話題,C/C++本來就書寫靈活,編譯器的優化是千差萬別,各有特點。這讓我想起了,譚浩強老師寫的《C語言程序設計》,我從一開始就不認為譚老師這本書怎么樣,但我也寫不出更好的書來。可以肯定的是,對于書中 ++i, i++,以及執行結果和編譯器高度相關的寫法大量出現。害人啊。換一個編譯器執行結果就不一樣。實在是誤人子弟。但這也是個不爭的事實,那就是,規范寫法,可以避免在多個編譯器中移植帶來的風險。
對于友人博客中所說,for(;;)和while(1)效率孰高孰低的討論,我個人覺得:
1.本身這兩種寫法無任何區別,和編譯器高度相關,這個是我們有能力則關心,沒能力關心也不需要太關心的事;
2.嵌入式代碼對C/C++寫法要求很高,建議有基礎的朋友們閱讀閱讀MISRA-C2004, 2008 和一些C++的國際級標準規范;
3.把主要的精力多放在代碼的規范上,而不是代碼的效率上。畢竟,單片機也使足夠的快了,絕大部分情況下成立;如果你是做代碼優化或者做算法的朋友們,建議多讀讀《計算機程序設計的藝術》一書,再掌握好一門匯編語言。將會有極大的用處。